
ULID - Une spécification d'identifiant unique triable lexicographiquement
Si vous êtes un professionnel en informatique, vous avez probablement déjà entendu parler de UUID, ce fameux ID universel aléatoirement généré sur 128 bits.
En voici un exemple :
e8fd12a3-17cd-48b7-b3a0-c8c3025fa3baULID est une spécification d’identifiant unique très similaire à UUID avec un avantage intéressant : il est ordonné dans le temps.
Un ULID généré à une date ultérieure aura donc un préfixe différent. En comparant 2 préfixes, il est donc possible de facilement connaître celui qui a été créé en premier, cela facilite grandement le tri !
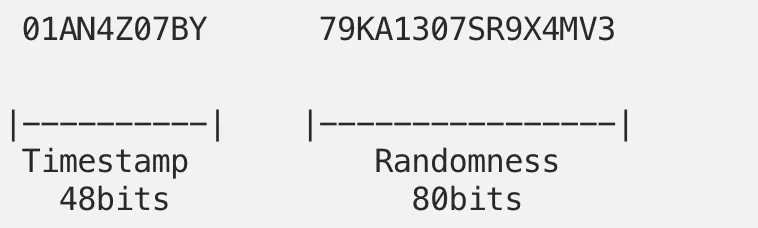
Il est généré via Crockford en base32, c’est-à-dire que les caractères I, L, O et U n’existent pas pour éviter les confusions, mais on peut également lui noter d’autres points intéressants :
- Compatibilité 128 bits avec UUID (même taille mais plus petit)
- 1,21 x 10^24 ULID uniques par milliseconde
- Triable lexicographiquement !
- Codé canoniquement sous forme de chaînes de 26 caractères, contrairement à l’UUID de 36 caractères
- Utilise le base32 de Crockford pour une meilleure efficacité et lisibilité (5 bits par caractère)
- Insensible à la casse
- Aucun caractère spécial (sécurisé pour les URL)
- Ordre de tri monotone (détecte et gère correctement la même milliseconde)
Si on fait un comparatif avec un UUID :
- Chaîne plus courte (26 caractères pour les ULID versus 36 pour les UUID)
- Un ULID est plus facilement lisible par un humain du fait de son encodage
- Possibilité de trier les IDs.
- Généralement plus performant :
- Dans les bases de données utilisant des index triés, les ULID peuvent améliorer les performances des requêtes car on tri sur l’index directement. Exemple dans les requêtes SQL, selon cet article Benchmarking UUID v4 vs ULID
- Lorsqu’on travaille avec des données de séries temporelles, les ULID (qui incluent une composante d’horodatage) peuvent être stockées et récupérées dans l’ordre chronologique sans tri supplémentaire.
Dans mes projets professionnels, je travaille énormément avec des bases de données DynamoDB d’AWS, et le tri sur ces bases n’est pas toujours super simple puisqu’il faut trier principalement sur des index. Avec les ULIDs, je vois comme avantage de pouvoir directement ordonner n’importe quel résultat sans avoir à rajouter un index spécifique, où à composer une clé plus complexe.
Au passage, la partie timestamp en Crockford peut monter jusqu’en 10889, notez-le dans vos agendas, le fameux bug de l’an 10889 arrive à grands pas.
Les ULID peuvent être initialisés avec une graine (seed), qui est un timestamp, afin de contrôler la partie temporelle, grâce à cela, on peut par exemple rejouer une migration pour migrer vers ULID, en connaissant sa date de création.
ulid(1469918176385) // 01ARYZ6S41TSV4RRFFQ69G5FAV
Enfin, il existe une implémentation déjà disponible pour beaucoup de langages différents, vous pouvez consulter la liste complète sur le repo officiel de ULID
Et vous, intéressé par cette spec ?