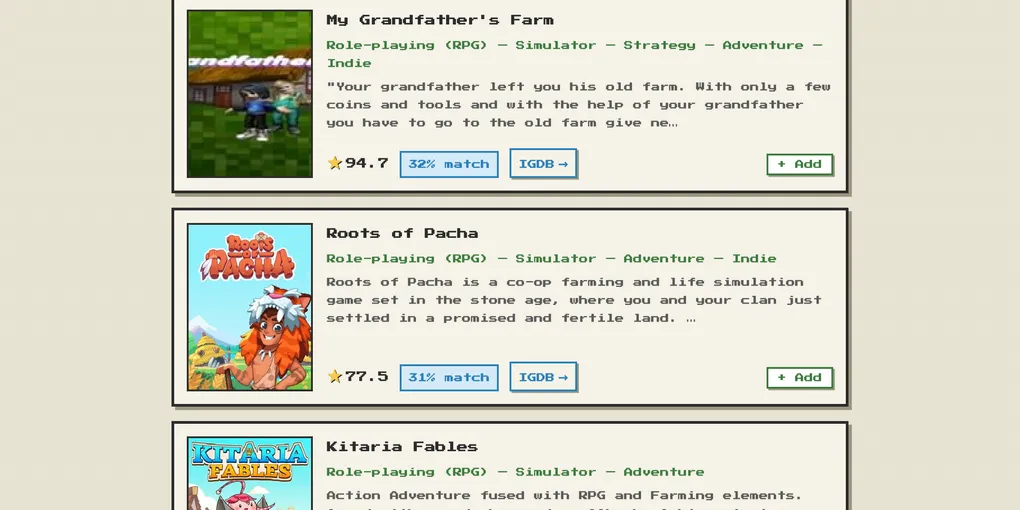
Un algorithme de Machine Learning de recommandation de contenu
Je me suis récemment demandé pourquoi les algorithmes de suggestion de contenu des applications populaires visaient systématiquement à côté pour me suggérer des contenus. Pourquoi est-ce toujours le même artiste qui est poussé sur Spotify ? Pourquoi sur Netflix, j’ai une avalanche de recommandations d’Anime Japonais alors que je n’en ai consommé qu’un seul ?
Et comment ça fonctionne, un système de suggestions ?
Alors je me suis mis en tête de comprendre comment fonctionnaient ces algorithmes en profondeur.
Content-Based Filtering VS Collaborative Filtering
Ce sont les 2 approches les plus connues dans l’univers des algorithmes de recommandations, ils sont en fait complémentaires
- Collaborative Filtering: Basé sur ce que les utilisateurs ont aimé, il vise à catégoriser les utilisateurs pour leur proposer du contenu que d’autres utilisateurs jugés similaires ont aimé.
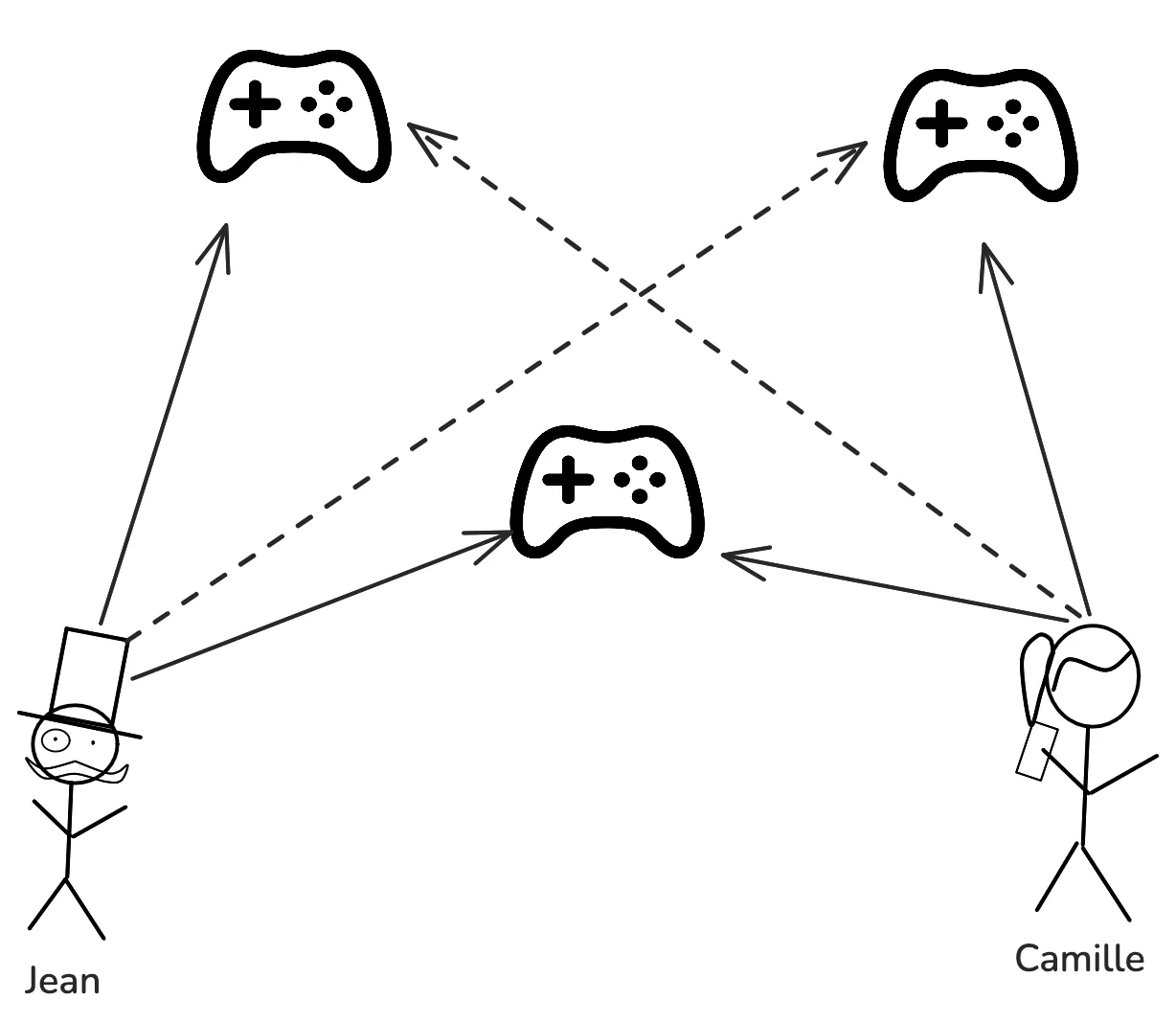
Ex: Si Jean a aimé Elden Ring et Minecraft, et que Claire a aimé Minecraft, alors elle aimera probablement aussi Elden Ring.
Cet algorithme souffre d’un problème de “Cold Start”, c’est-à-dire qu’il est dépendant d’une certaine activité sur votre application.
- Content-Based Filtering: Prend souvent la forme d’une section “Titre Similaire” en bas d’un détail d’un film. Il vise à identifier les contenus qui ressemblent à d’autres contenus.
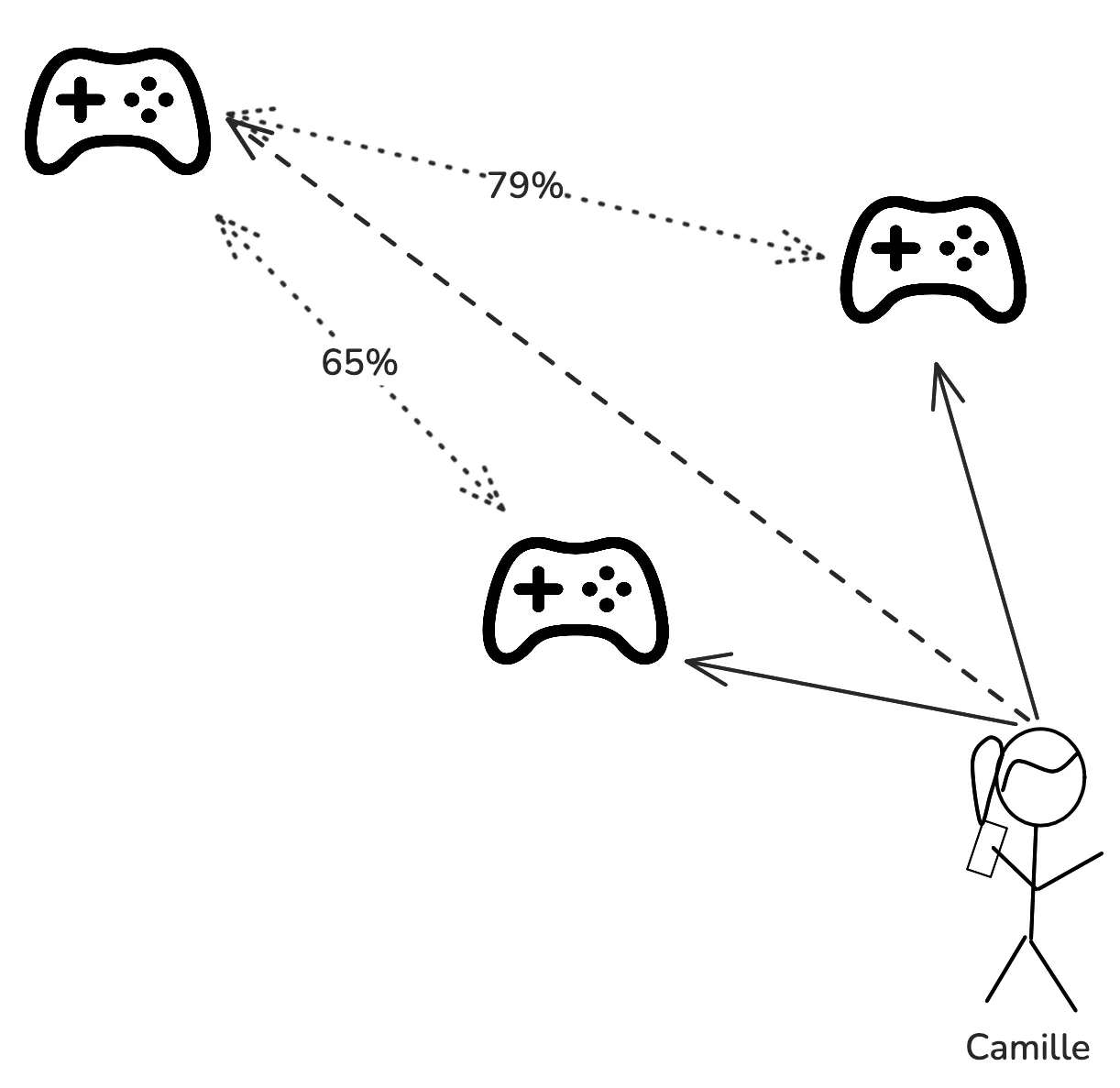
Ex: Si Camille a aimé Minecraft et Elden Ring, et qu’on détecte que Les Sims 4 est très proche des deux jeux avec des scores de 65% et de 79% de similarités, alors on peut lui recommander ce jeu.
L’avantage de cet algorithme est qu’il peut fonctionner dès le début puisqu’il n’utilise que votre contenu pour pousser des recommandations.
À vrai dire, ces deux systèmes de suggestions utilisent le même algorithme qui s’appelle “Cosin Similarities” que nous allons voir plus en détail dans un instant.
Dans la vraie vie, la plupart des systèmes de suggestions poussés utilisent les deux algorithmes simultanément, boostés au Deep Learning et à d’autres techniques de mises en avant purement “Marketing”.
Ils intègrent aussi des “tendances” sur la durée. Par exemple si sur ma plateforme, j’ai subitement un pic de visionnage pour Interstellar, alors je vais le mettre en page d’accueil parce que visiblement, ce film suscite de l’intérêt en ce moment.
Bon alors, comment faire un algorithme qui m’aide à identifier du contenu que je vais aimer ?
L’objectif de ce petit projet est de m’aider à trouver des jeux vidéo qui seraient susceptibles de me plaire, en passant une liste de jeux vidéo qui m’ont plu.
1: Un bon jeu de données
J’ai choisi les jeux vidéo car le nombre de contenu est un peu plus limité que les films ou séries, et je suis d’ailleurs tombé sur une API assez pratique: IGDB.com. En Machine Learning, on dit souvent qu’un bon algo de ML, ça passe avant tout par de bonnes données !
À l’aide de l’API, j’ai simplement crawler la liste de jeux déjà sortis qui possédaient au moins un certain nombre d’avis, afin d’exclure les contenus jugés non pertinents.
À l’aide du résultat, j’ai créé un fichier games.csv, en manipulant quelques champs et surtout en enlevant les champs inutiles pour ne pas surcharger le système.
Grosso modo, cela me donne un truc comme ça
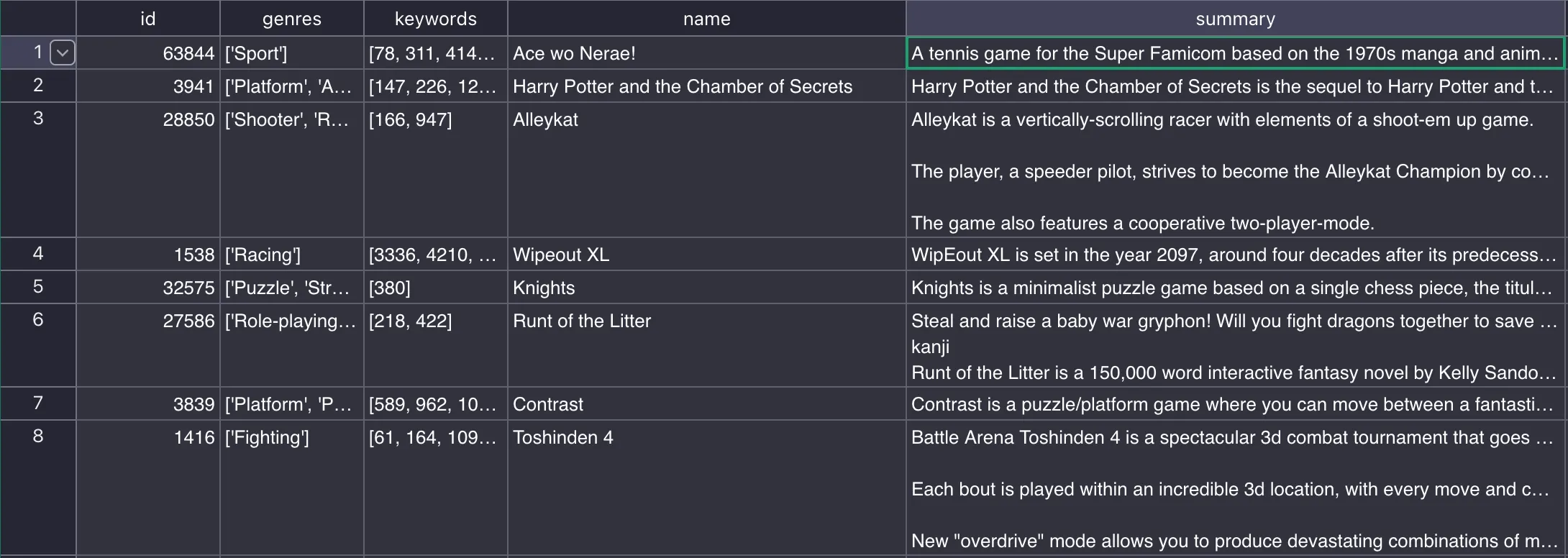
Ici j’ai identifié 3 champs susceptibles de m’aider à associer des jeux ensembles:
- Summary: un texte de description
- Genres: un tableau de chaînes limité, il y en a en tout une vingtaine.
- Tags: un tableau de chaînes beaucoup plus permissif, mais aussi beaucoup plus précis, il y en a 140 000 dans l’API.
J’ai aussi un champ Rating: La note sur 100, ça pourrait être utile même si les jeux “mainstream” auront tendance à ressortir en premier si j’y prête trop attention.
2: Vectoriser la donnée
Là, on ne rigole plus. L’idée est que pour définir si un jeu est “proche” d’un autre, je dois le catégoriser. C’est-à-dire transformer cette donnée pour être capable plus tard d’identifier les rapprochements ou les éloignements avec une autre donnée de même type. Il n’y a pas 36 solutions, on va faire des matrices. Et pour faire des matrices sur du texte, le mieux est l’algorithme TF-IDF.
Term Frequency X Inverse Document Frequency (TF-IDF)
C’est un algorithme de comptage de mots accessible super facilement dans la librairie scikit-learn puisqu’on appelle juste la fonction:
tfidf = TfidfVectorizer(stop_words="english")
tfidf_matrix = tfidf.fit_transform(gamesDF["summary"])stop_words représente la langue du texte, en fait il ignorera tous les mots de liaison (déterminants, conjonctions etc) pour se concentrer sur les mots les plus importants de la phrase.
TF-IDF va alors dresser une matrice où chaque donnée est une ligne, et chaque mot trouvé est une colonne. On mettra comme valeur le nombre de ce mot trouvé. Par exemple pour un corpus de 2 phrases:
Ce jeu est vachement chouetteUn jeu où l'on incarne une chouette magique
On aurait la matrice suivante:

Ici, les mots qui se retrouvent dans les 2 phrases ont une valeur plus basse à 0,35 que les mots présents dans une seule phrase.
C’est ça le twist ! Plus un mot est présent dans un jeu de données, moins il a de poids.
Autrement dit, on multiplie la fréquence d’un terme dans un document par l’inverse de la présence de ce terme dans tout le corpus !
Pour un tableau de chaînes, comme pour nos genres et nos keywords, c’est le même principe, mais on va passer ce champ dans une fonction prévue pour ça: le MultiLabelBinarizer.
mlb = MultiLabelBinarizer()
XBin = mlb.fit_transform(gamesDF["keywords"])
tfidf = TfidfTransformer()
tfidf_matrix = tfidf.fit_transform(XBin)3: Trouver les contenus similaires
Là on a déjà fait le plus dur, on a catégorisé nos contenus.
Pour trouver un contenu proche d’un autre, on utilise un algorithme appelé Cosin Similarites.
Cosin Similarites
Prenons nos 2 vecteurs. Pour savoir la distance qui les sépare, cela revient à calculer l’angle entre eux. Et donc le cosinus !
Le cosinus de similarité entre 2 vecteurs est appelé ‘θ’.
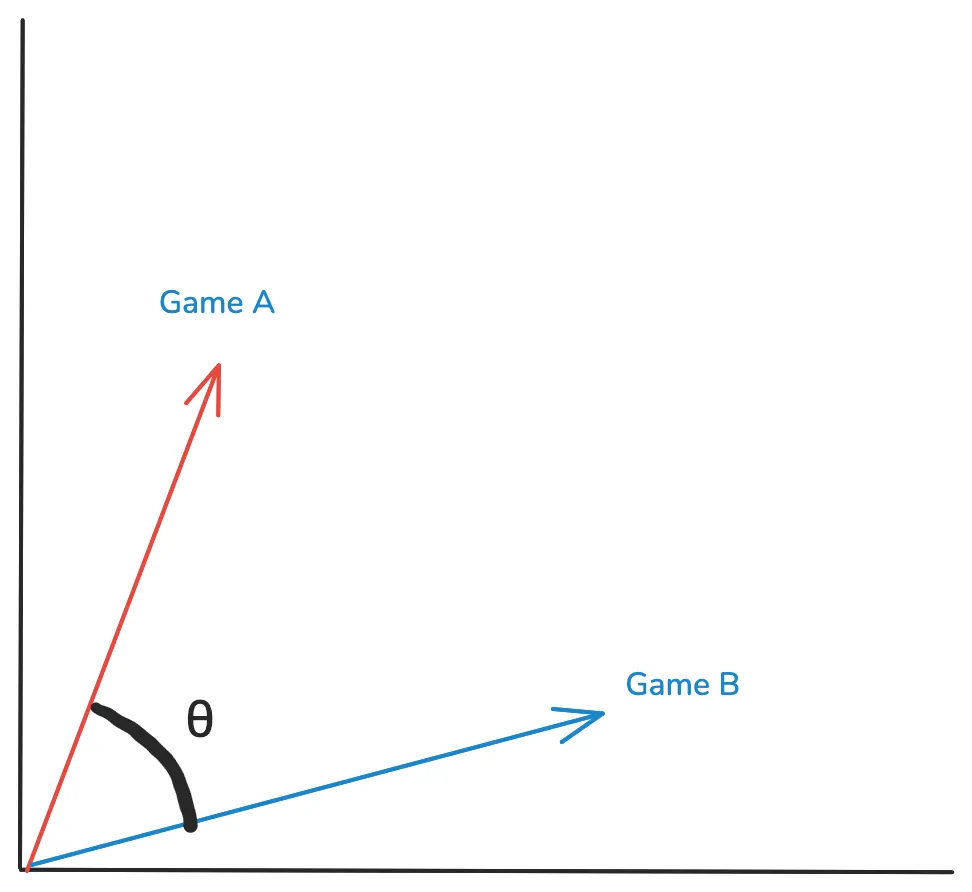
- Si θ = 0°, les vecteurs ‘x’ et ‘y’ sont superposés, cela prouve qu’ils sont similaires.
- Si θ = 90°, les vecteurs ‘x’ et ‘y’ sont différents.
- Si θ = 180°, les vecteurs sont aux opposés.
La fonction permet aussi de prendre une liste de contenus.
Ainsi si j’ai aimé 5 contenus différents, la fonction va me retourner une liste de résultats avec un score, qui est la moyenne de similarités détectées sur les différents contenus.
On va le faire pour nos 3 champs (summary, genres & keywords), on aura 3 listes de similarités différentes.
def __getScores(self, tfidf_matrix, column_name: str):
sim = cosine_similarity(tfidf_matrix, tfidf_matrix[self.selectedIndices])
scores = sim.mean(axis=1)
result = self.gamesDF.copy()
result[column_name] = scores
return result.drop(index=self.selectedIndices)selectedIndices c’est simplement un tableau contenant les indexs de nos jeux préférés, dans le tableau de jeux.
4: L’étape de concaténation
On a fait nos matrices pour les 3 champs (summary, genres et keywords), et identifié les similarités.
Il suffit ensuite de merger les 3 retours, avec un coefficient permettant de pondérer les résultats, pour bien finir le tout !
Dans mon cas le genre ne me semblait pas très parlant car pas assez précis. Certains jeux catégorisés comme Simulation n’en étaient pas vraiment.
On va appliquer un coefficient plus faible sur le genre pour qu’on en tienne moins compte.
D’ailleurs, j’en ai profité pour rajouter un petit boost pour les jeux bien notés, car on se le dit, il y a des jeux très bons, et des moins bons !
recommendations["score"] = (
recommendations["score_summaries"] * 0.3
+ recommendations["score_genres"] * 0.1
+ recommendations["score_keywords"] * 0.3
+ (recommendations["total_rating"] / 100) * 0.3
)Conclusion
Et voilà ! On a fini notre algorithme de Content-Based Filtering !
Si je lui passe en entrée 3 jeux, l’algorithme roule en 1s et me retourne une liste de résultat plutôt probant !
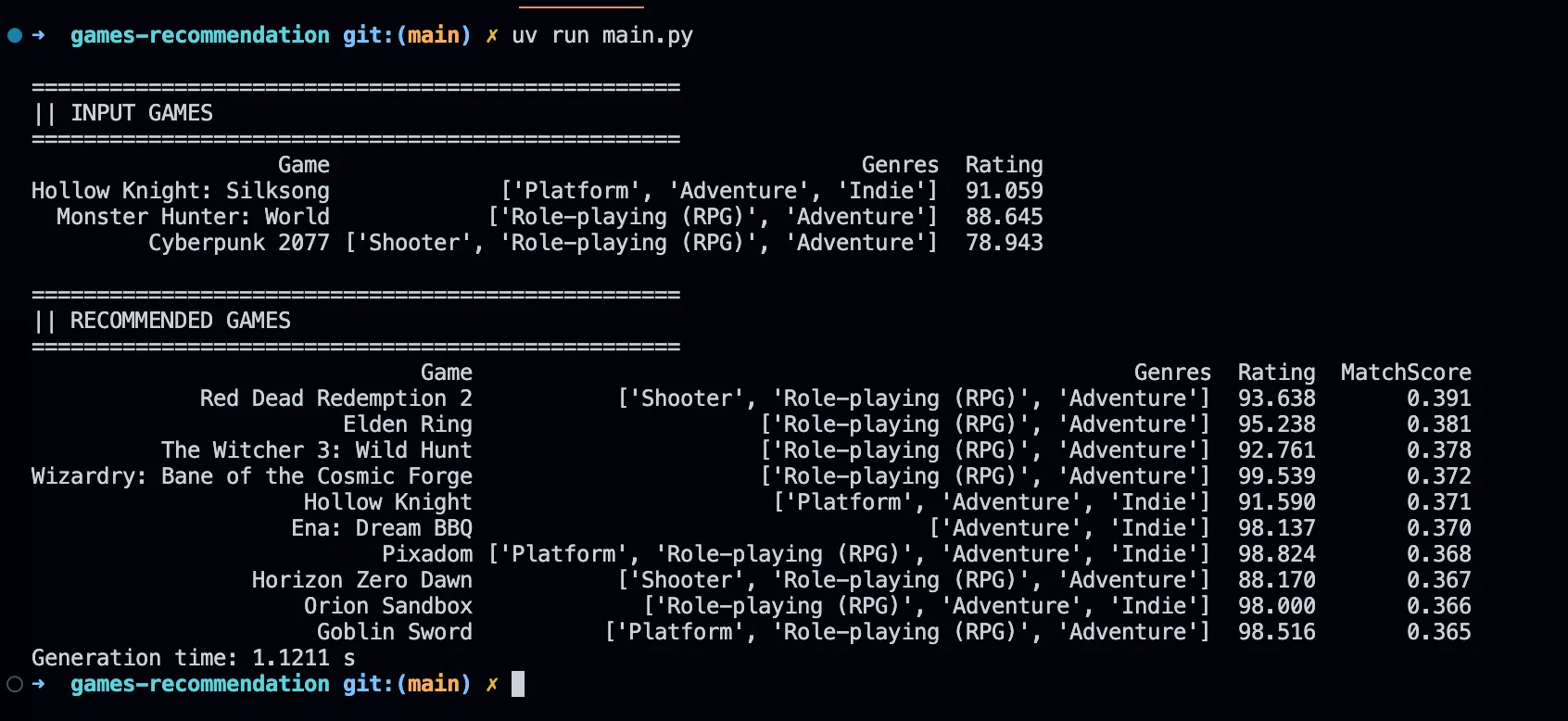
Au final, la complexité est complètement abstraite par scikit-learn. Il existe encore beaucoup d’autres fonctions de machine learning dans cette librairie que je n’ai pas eu le temps d’explorer.
Vous pouvez retrouver l’entièreté du code source sur mon github.